In the past two years, diffusion models have revolutionized and taken over the field of generative models. In particular, the paper by Ho et al. [1] accelerated this trend. However, in my opinion, one of the most seminal works in this field dates back to 2010 with the technical report of Pascal Vincent [2] that uncovers the link between score matching and denoising autoencoders and derives the denoising-score matching objective. In this blog post I would like to give an intuitive explanation of score-based modeling and introduce the denoising score-matching objective of [2], all accompanied by some visualizations in 1D space.
Generative Modeling
Given data samples  drawn from the true data distribution
drawn from the true data distribution  , in generative modeling we usually try to learn a model that allows us to synthesize new data. While implicit generative models, like Generative Adversarial Networks (GANs), learn the sampling process itself, explicit models try to directly model the probability density function (pdf) in order to sample from this distribution. We can represent such a pdf with an energy-based model
, in generative modeling we usually try to learn a model that allows us to synthesize new data. While implicit generative models, like Generative Adversarial Networks (GANs), learn the sampling process itself, explicit models try to directly model the probability density function (pdf) in order to sample from this distribution. We can represent such a pdf with an energy-based model
![\[p_\theta (\mathbf{x}) = \frac{e^{- f_\theta (\mathbf{x})}}{Z_\theta}\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-5310c6bd4b13dd42fff04f0e2fd5d955_l3.png "Rendered by QuickLaTeX.com")
where  are the learnable parameters of the model,
are the learnable parameters of the model,  is a normalizing constant or partition function that ensures that
is a normalizing constant or partition function that ensures that  , and
, and  is the energy-function or unnormalized probability model, which is usually a deep neural network.
is the energy-function or unnormalized probability model, which is usually a deep neural network.
One approach to learning this model would be traditional maximum-likelihood estimation, where we try to find the parameters that maximize the joint density  When we insert the energy-based model into the MLE objective we get
When we insert the energy-based model into the MLE objective we get
![\[\mathbb{E}_{p(\mathbf{x})}} [- \log p_\theta (\mathbf{x})] = \mathbb{E}_{p(\mathbf{x})} [\log f_\theta (\mathbf{x}) - \log Z_\theta]\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-154cead0f33499d113002988204867e1_l3.png "Rendered by QuickLaTeX.com")
The output of the energy-function or neural network  is easy to evaluate, however, in order to ensure that the pdf integrates to one, we need to find the normalizing constant , which is usually intractable.
is easy to evaluate, however, in order to ensure that the pdf integrates to one, we need to find the normalizing constant , which is usually intractable.
Score Function
Score-based modeling circumvents the problem of finding the normalizing constant by modeling the score function, which is defined as
![\[s(\mathbf{x}) = \triangledown_{\mathbf{x}} \log p_\theta (\mathbf{x})\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-82e152534632fcdf06d461aa9dec5d52_l3.png "Rendered by QuickLaTeX.com")
The score is essentially the gradient of the true data log-likelihood evaluated on any point  in data space. Intuitively, given an arbitrary point , the score at this point tells us in which direction we would need to move to get to a higher density region.
in data space. Intuitively, given an arbitrary point , the score at this point tells us in which direction we would need to move to get to a higher density region.
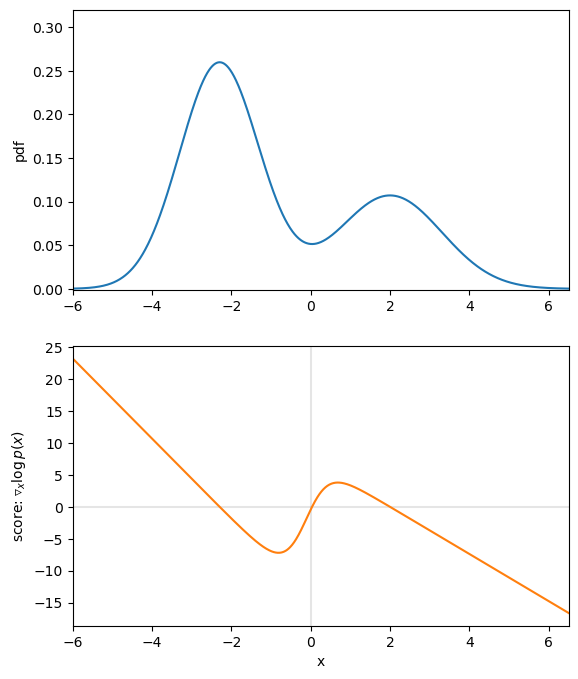
Let’s assume our true data distribution is a simple univariate Gaussian Mixture Model (GMM), as displayed in figure 1. The value of the corresponding score function at each position , tells us the direction of higher density. For example, if we are at  we can see that the score is positive and thus, if we want to make slightly more likely under
we can see that the score is positive and thus, if we want to make slightly more likely under  , we need to move to the right. Contrarily, if we evaluate the point
, we need to move to the right. Contrarily, if we evaluate the point  , the negative score tells us that for a higher density region we need to move to the left.
, the negative score tells us that for a higher density region we need to move to the left.
Score-based model
In order to model the score function, we define a score-based model  , parametrized by , which tries to approximate the true score function
, parametrized by , which tries to approximate the true score function  . If we insert the definition of the energy-based model and apply the logarithm quotient rule we get
. If we insert the definition of the energy-based model and apply the logarithm quotient rule we get
![\[\begin{aligned}s_\theta (\mathbf{x})&= \triangledown_{\mathbf{x}} \log p_\theta(\mathbf{x}) \\&= \triangledown_{\mathbf{x}} \log \frac{e^{- f_\theta (\mathbf{x})}}{Z_\theta} \\&= \triangledown_{\mathbf{x}} \log e^{- f_\theta (\mathbf{x})} - \underbrace{\triangledown_{\mathbf{x}} \log Z_\theta}_{=0} \\&= - \triangledown_{\mathbf{x}} f_\theta (\mathbf{x})\end{aligned}\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-adf3a4366c41a36982ffa5a8f03428e7_l3.png "Rendered by QuickLaTeX.com")
With that we can see that our score-based model is independent of the normalizing constant , as the gradient w.r.t. the input develops to zero. Hence, in contrast to MLE, we model an unconstrained function without the need for normalization. Intuitively, instead of learning the pdf with the corresponding partition function, our model learns some kind of navigation map that, at every point in data space, leads us to higher density regions.
Training this model then just breaks down to a simple regression problem known as score-matching, where  should learn to best match the gradient of the true log likelihood at every point . The objective can be defined as the Euclidean distance (Fisher divergence) between the true score and our score-based model
should learn to best match the gradient of the true log likelihood at every point . The objective can be defined as the Euclidean distance (Fisher divergence) between the true score and our score-based model
![\[\begin{aligned}J(\theta)&= \mathbb{E}_{p(\mathbf{x})} [\lVert s_\theta (\mathbf{x}) - s(\mathbf{x})\rVert^2_2] \\&= \mathbb{E}_{p(\mathbf{x})} [\lVert s_\theta (\mathbf{x}) - \triangledown_{\mathbf{x}} \log p(\mathbf{x})\rVert^2_2]\end{aligned}\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-36c08584b469ef104fa9da1f0aefaf81_l3.png "Rendered by QuickLaTeX.com")
However, this objective brings up two problems. First, it requires us to have access to the true score of the data distribution, which we usually don’t have. And second, it fails to learn good estimates of the score in low density regions, as we weight it with when we evaluate the expectation  .
.
The paper of Vincent [2] addresses both of these problems by linking score matching to the Denoising Autoencoder objective.
Denoising Score-Matching
The general goal of Denoising Autoencoders is to learn a model that denoises a corrupted sample  to get back to the original sample .
to get back to the original sample .
We can easily create a perturbed version of our original dataset by simply adding Gaussian noise, controlled by the variance  , to each data sample s.t. the corrupted version of
, to each data sample s.t. the corrupted version of  is defined as
is defined as  with
with  .
.
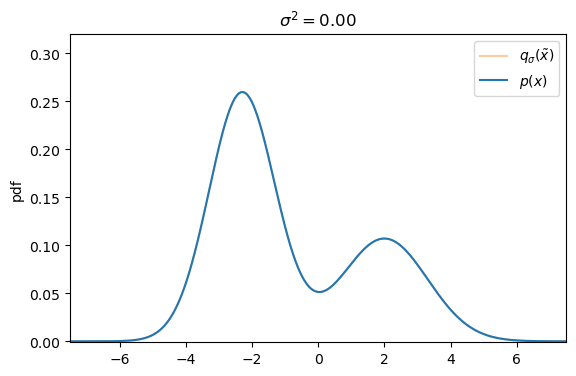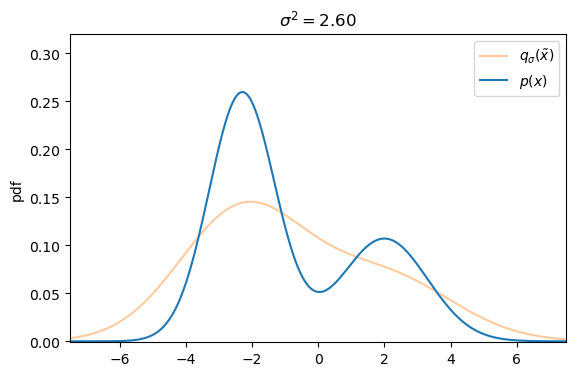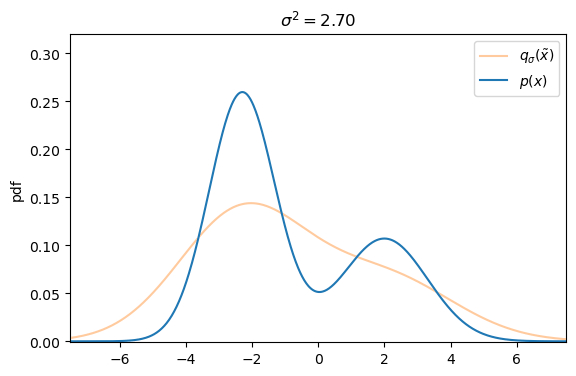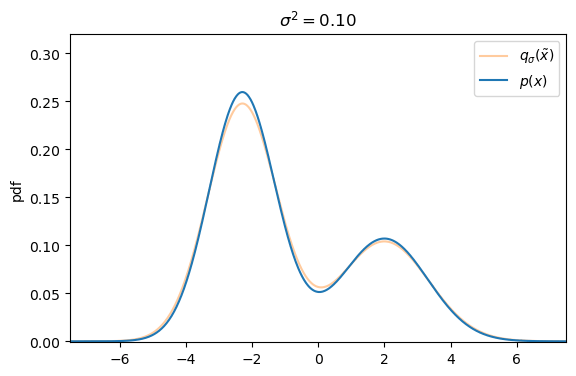
Defining the explicit score-matching objective for the corrupted dataset  yields
yields
![\[\begin{aligned}J_{explicit}(\theta) = \mathbb{E}_{q_\sigma (\tilde{\mathbf{x}})}[ \frac{1}{2}\lVert s_\theta (\tilde{\mathbf{x}}) -\triangledown_{\tilde{\mathbf{x}}} \log q_\sigma (\tilde{\mathbf{x}})\rVert^2_2].\end{aligned}\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-fd6493fd0a209c311f4afc0a355d6fc1_l3.png "Rendered by QuickLaTeX.com")
So far we still cannot evaluate the score. However, in an elegant proof in the appendix of the original paper [2], Vincent shows that this objective can be considered as equivalent to the following denoising score matching (DSM) objective
![\[\begin{aligned}J_{DSM_\sigma}(\theta) =\mathbb{E}_{q_\sigma (\tilde{\mathbf{x}}, \mathbf{x})}[ \frac{1}{2} \lVert s_\theta (\tilde{\mathbf{x}}) -\triangledown_{\tilde{\mathbf{x}}} \log q_\sigma (\tilde{\mathbf{x}} | \mathbf{x})\rVert^2_2]\end{aligned}\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-6b67a8ba7fe7e72c0c14eab152e92c17_l3.png "Rendered by QuickLaTeX.com")
over the joint density  .
.
While  is a complex distribution and we thus cannot evaluate it,
is a complex distribution and we thus cannot evaluate it,  follows a normal distribution
follows a normal distribution  with mean and variance , as
with mean and variance , as
![\[\tilde{\mathbf{x}} = \mathbf{x} + \epsilon \iff \tilde{\mathbf{x}} \sim \mathcal{N}(\mathbf{x}, \sigma^2 \cdot I)\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-d3d35489f8e84b90596e75b94f733348_l3.png "Rendered by QuickLaTeX.com")
with (see Convolution of probability distributions).
This allows us to easily derive the gradient
![\[\begin{aligned}\triangledown_{\tilde{\mathbf{x}}} \log q_\sigma (\tilde{\mathbf{x}} | \mathbf{x})&= \triangledown_{\tilde{\mathbf{x}}} \log \mathcal{N}(\mathbf{x}, \sigma^2 \cdot \mathbf{I})\\&= \triangledown_{\tilde{\mathbf{x}}} \log \frac{\exp(-\frac{1}{2} (\tilde{\mathbf{x}} - \mathbf{x})^T \cdot (\sigma^2 \cdot \mathbf{I})^{-1} \cdot(\tilde{\mathbf{x}} - \mathbf{x}))}{\sqrt{(2\pi)^d | \sigma^2 \cdot \mathbf{I} |}}\\&= \triangledown_{\tilde{\mathbf{x}}}\log \exp(-\frac{1}{2} (\tilde{\mathbf{x}} - \mathbf{x})^T\cdot (\sigma^2 \cdot \mathbf{I})^{-1} \cdot(\tilde{\mathbf{x}} - \mathbf{x}))\\ & \hspace{0.8cm} - \underbrace{\triangledown_{\tilde{\mathbf{x}}} \log \sqrt{(2\pi)^d | \sigma^2 \cdot \mathbf{I} |}}_{= 0} ]\\&= -\frac{1}{2\sigma^2} \triangledown_{\tilde{\mathbf{x}}}(\tilde{\mathbf{x}} - \mathbf{x})^T \cdot \mathbf{I} \cdot (\tilde{\mathbf{x}} - \mathbf{x})\\&= -\frac{1}{2\sigma^2} \triangledown_{\tilde{\mathbf{x}}} (\tilde{\mathbf{x}} - \mathbf{x})^2\\&= - \frac{(\tilde{\mathbf{x}} - \mathbf{x})}{\sigma^2} = \frac{(\mathbf{x} - \tilde{\mathbf{x}})} {\sigma^2}.\end{aligned}\]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-31b6d7a566923d7021437d483db0811c_l3.png "Rendered by QuickLaTeX.com")
Intuitively, the gradient corresponds to the direction of moving from  back to the original (i.e., denoising it), and we want our score-based model
back to the original (i.e., denoising it), and we want our score-based model  to match that as best as it can.
to match that as best as it can.
Figure 3 visualizes that for the 1D case. We can see that the direction of the denoising score  almost perfectly matches the direction of the ground truth score
almost perfectly matches the direction of the ground truth score  . Thus, we found an appropriate target for our score-matching objective, so that we can learn the score function.
. Thus, we found an appropriate target for our score-matching objective, so that we can learn the score function.
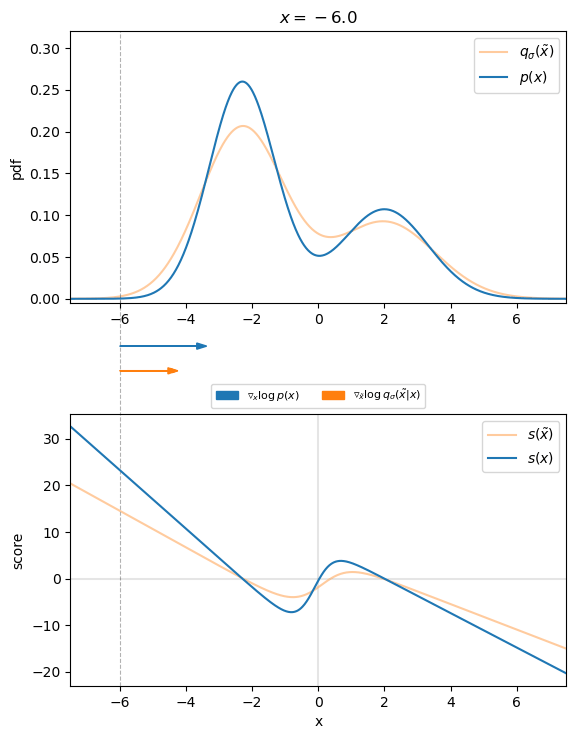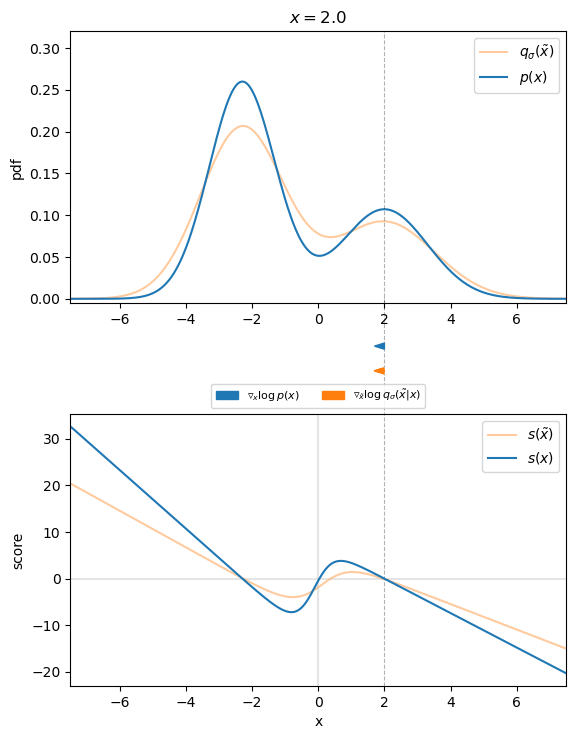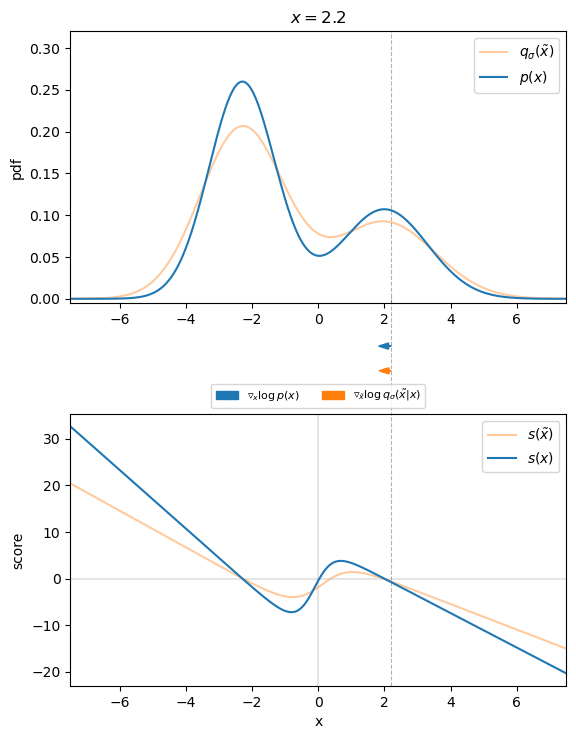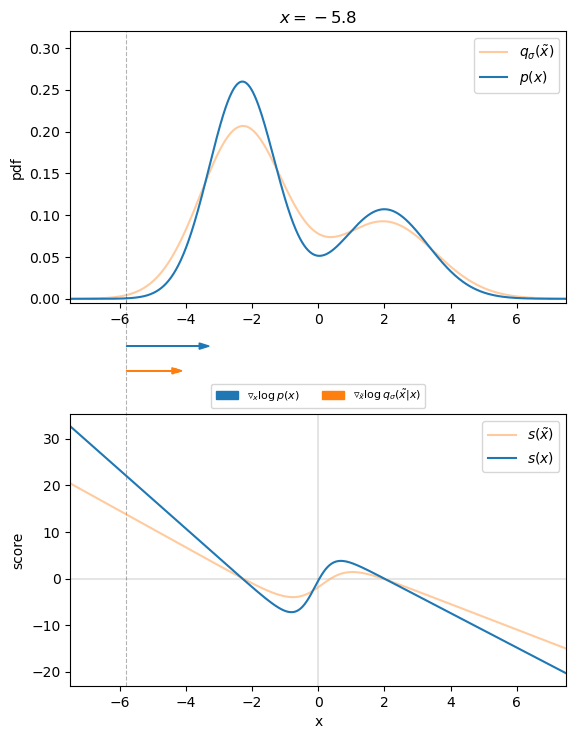
 , with corresponding scores. Arrows indicate the direction of the ground truth and denoising score for different values of .
, with corresponding scores. Arrows indicate the direction of the ground truth and denoising score for different values of .Conclusion
With the denoising score matching objective we are able to circumvent the problem of not having access to the true score of our data distribution and additionally, with larger noise scales, also get signals in low density regions.
On a first glance it seems like there exists a trade-off between small versus large additive noise scales . With small noise scales the denoising score approximates the ground truth score well, but we cannot cover much of the low density regions, whereas with larger noise scales we can cover more of the low density regions, but our targets are less accurate, as they may not match the actual score anymore.
However, as we can easily generate different noisy versions of our dataset, we can sidestep this problem by simply using multiple noise scales. Intuitively, we populate the whole data space with a large noise scale, s.t. in low density regions we get a rough direction in which to move. Then, iteratively, we decrease our noise scale and get a finer and finer direction towards regions with higher density. This is exactly what happens in Denoising Diffusion Probabilistic Models (DDPM) [1]. Visually speaking, DDPMs learn a navigation map in data space that guides them to the actual data manifold.
References
[1] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840-6851.
[2] Vincent, P. (2011). A connection between score matching and denoising autoencoders. Neural computation, 23(7), 1661-1674.
[3] Song, Y. (2021). Blog “Generative Modeling by Estimating Gradients of the Data Distribution”. https://yang-song.net/blog/2021/score/.