In a past university project my teammates and I were researching which parts of a face are the most discriminative for a convolutional neural network to classify emotions. For that we trained several facial emotion recognition models with TensorFlow on two databases: FER+ and RAF-DB. The final model architecture as well as model results are shortly presented in this post.
Pre-Processing
The input to our final model is a fixed-size  RGB image. The images in each dataset were standardized to have zero mean and unit variance per color channel, which was done by subtracting the mean RGB value, computed on the training set, from each pixel and dividing the result by the RGB standard deviation of the training set. To improve robustness of our model against translation, rotation, and scaling, as well as to artificially enrich our data, we augmented our dataset by randomly rotating (
RGB image. The images in each dataset were standardized to have zero mean and unit variance per color channel, which was done by subtracting the mean RGB value, computed on the training set, from each pixel and dividing the result by the RGB standard deviation of the training set. To improve robustness of our model against translation, rotation, and scaling, as well as to artificially enrich our data, we augmented our dataset by randomly rotating ( ), scaling (
), scaling ( of the width/height), and horizontally flipping the images.
of the width/height), and horizontally flipping the images.
Model Architecture
Our network architecture is visualized in figure 1 and loosely follows the concept of VGGNet [1]. For the basic building blocks we stack two or three convolutional layers with  filters with stride
filters with stride  , followed by a max pooling layer with stride
, followed by a max pooling layer with stride  . Stacking convolutional layers with small filter size effectively achieves a similar receptive field as a convolution with a larger filter size. It additionally incorporates extra non-linearities and reduces the number of parameters [1]. After each down sampling operation we increase the number of filters. Inputs to each convolutional layer are zero padded, such that the spatial resolution is preserved (same padding, as applied in [1,2] ). We use batch normalization (BN) [3] directly after each convolution and before non-linearity, as it is applied in [2,3]. Batch normalization speeds up training and allows us to use larger initial learning rates [3]. For non-linearity we use ReLU after each BN and therefore initialize the weights according to [4]. Directly after the last convolution and before the final classification layer we use global average pooling (GAP) which spatially averages each feature map of the last convolutional layer, resulting in a scalar value per feature map [5]. Following current state-of-the-art approaches [2,3,5,6,7], this vector is then directly fed into the final output layer with softmax activation. The described architecture consists of
. Stacking convolutional layers with small filter size effectively achieves a similar receptive field as a convolution with a larger filter size. It additionally incorporates extra non-linearities and reduces the number of parameters [1]. After each down sampling operation we increase the number of filters. Inputs to each convolutional layer are zero padded, such that the spatial resolution is preserved (same padding, as applied in [1,2] ). We use batch normalization (BN) [3] directly after each convolution and before non-linearity, as it is applied in [2,3]. Batch normalization speeds up training and allows us to use larger initial learning rates [3]. For non-linearity we use ReLU after each BN and therefore initialize the weights according to [4]. Directly after the last convolution and before the final classification layer we use global average pooling (GAP) which spatially averages each feature map of the last convolutional layer, resulting in a scalar value per feature map [5]. Following current state-of-the-art approaches [2,3,5,6,7], this vector is then directly fed into the final output layer with softmax activation. The described architecture consists of  parameters, of which
parameters, of which  are to be trained.
are to be trained.

Training
We trained our model with a batch size of  , using Adam optimizer [8] with the default parameters provided by tensorflow [9]. The initial learning rates were
, using Adam optimizer [8] with the default parameters provided by tensorflow [9]. The initial learning rates were  and
and  for the RAF-DB and FER+ model respectively. Every time the validation loss stopped improving, we decreased the learning rate by a factor of
for the RAF-DB and FER+ model respectively. Every time the validation loss stopped improving, we decreased the learning rate by a factor of  . Within
. Within  epochs of training the learning rate was decreased times for the FER+ and
epochs of training the learning rate was decreased times for the FER+ and  times for the RAF-DB model. For training we used the standard cross-entropy loss, but as in [10] taking the empirical label distribution of the taggers per image as the target instead of the one-hot encoded major vote. Both models were trained on a NVIDIA GeForce GTX 1050 Ti GPU.
times for the RAF-DB model. For training we used the standard cross-entropy loss, but as in [10] taking the empirical label distribution of the taggers per image as the target instead of the one-hot encoded major vote. Both models were trained on a NVIDIA GeForce GTX 1050 Ti GPU.
Results
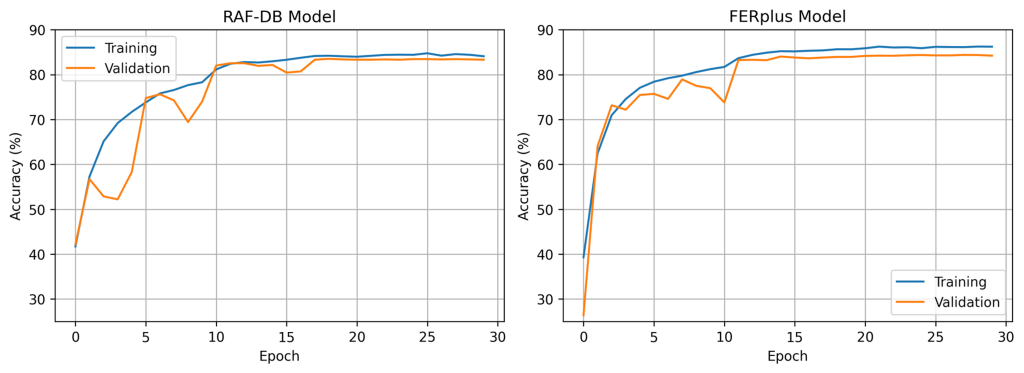
The training and validation accuracies over all training epochs for the FER+ and RAF-DB models are displayed in figure 2. One can clearly see that for both models the accuracy stagnates after around  epochs.
epochs.
The accuracies for each model and for both, the validation and the held out test dataset, are available in the table below.
| RAF-DB model | FER+ model | |
| Validation Accuracy |  % % |  % % |
| Test Accuracy |  % % |  % % |
The final FER+ model achieved a validation accuracy of % ( images) and a test accuracy of % (
images) and a test accuracy of % ( images). These results are comparable to the results obtained by Barsoum et al. [10], differing only slightly (
images). These results are comparable to the results obtained by Barsoum et al. [10], differing only slightly ( %), but having significantly less parameters. Our model has approximately
%), but having significantly less parameters. Our model has approximately  trainable parameters in contrast to approximately
trainable parameters in contrast to approximately  million trainable parameters in the model of [1]. Hence, we were able to achieve similar results by only using about
million trainable parameters in the model of [1]. Hence, we were able to achieve similar results by only using about  % of the parameters.
% of the parameters.
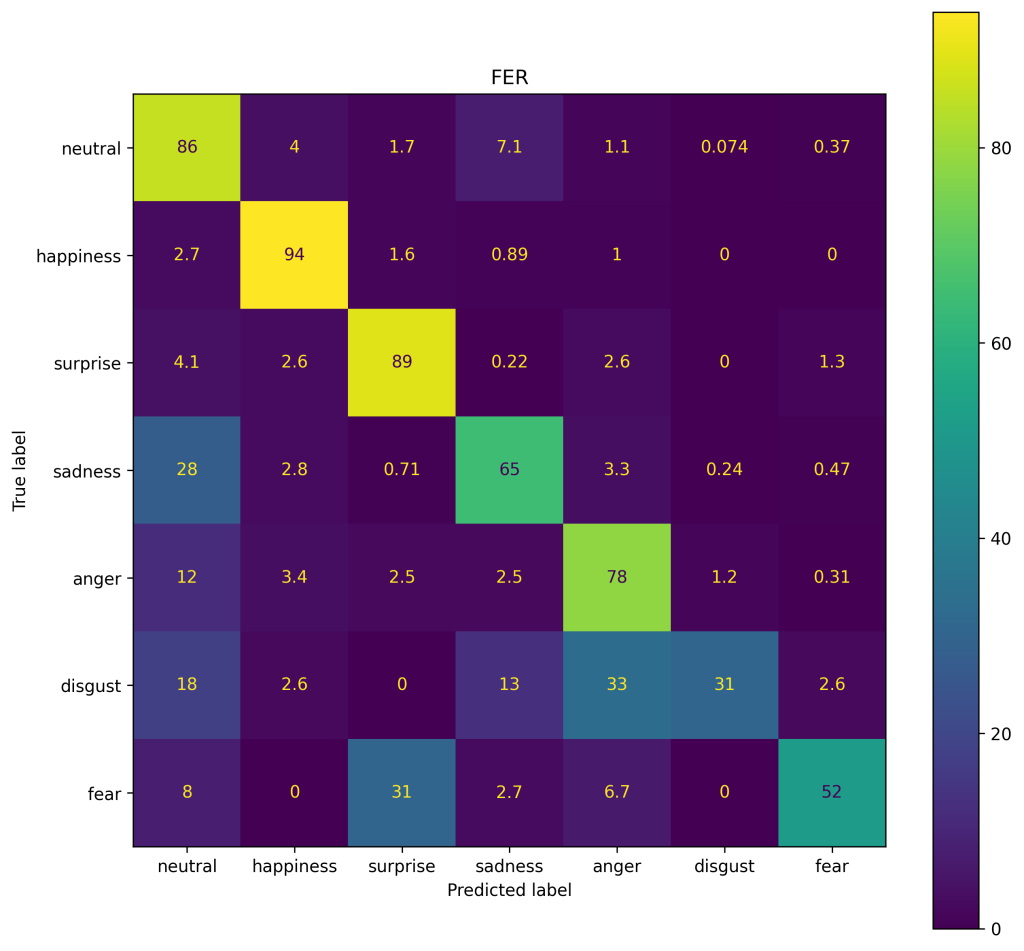
The confusion matrix of the FER+ model in figure 3 shows that the model particularly has problems classifying disgust, and heavily confuses it with an angry or neutral facial expressions. Fear and surprise are also often confused.
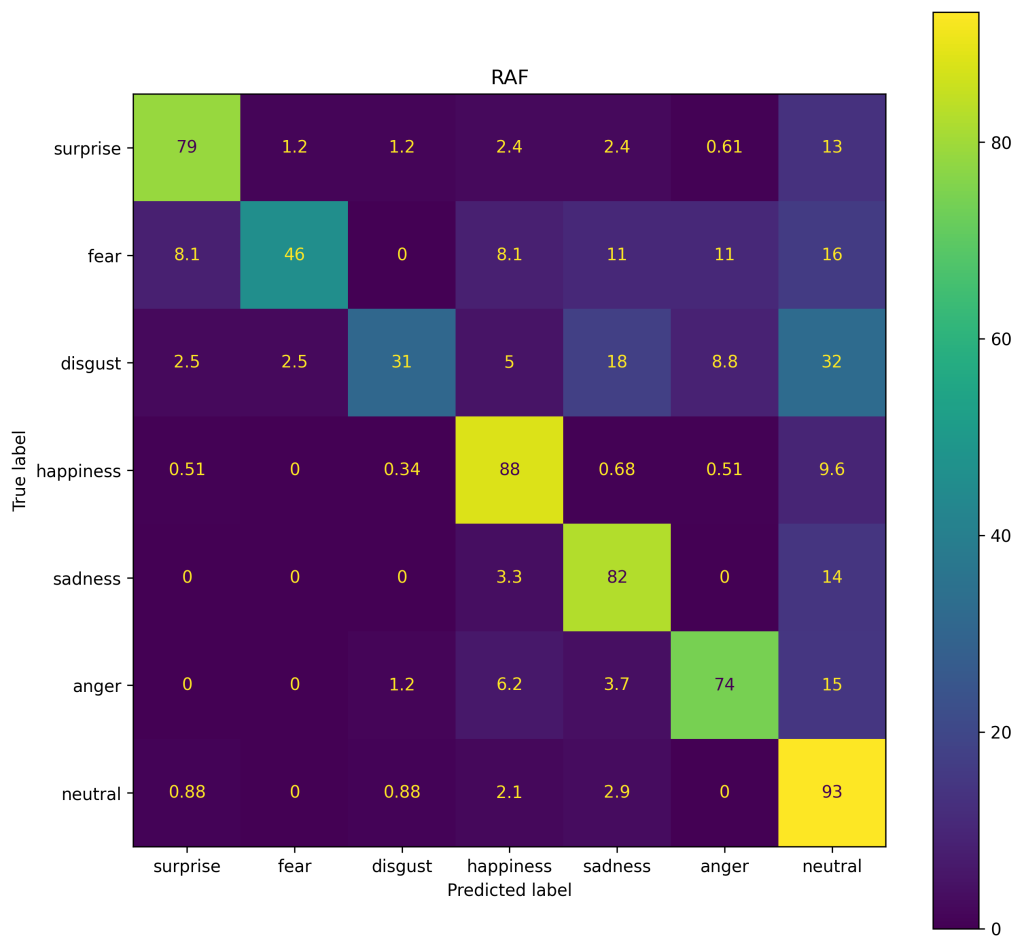
The accuracies of the model trained on RAF-DB are slightly worse than in the FER+ model. The validation accuracy of the RAF-DB model was % on the validation set and % on the test set. Similar to the FER+ model, the RAF-DB model had problems discriminating between fear and disgust, confusing both either with a neutral, sad or angry facial expression (see figure 4).
References
[1] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
[2] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[3] Ioffe, S., & Szegedy, C. (2015, June). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning (pp. 448-456). PMLR.
[4] He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision (pp. 1026-1034).
[5] Lin, M., Chen, Q., & Yan, S. (2013). Network in network. arXiv preprint arXiv:1312.4400.
[6] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., … & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
[7] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818-2826).
[8] Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
[9] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, … & Xiaoqiang Zheng.
TensorFlow: Large-scale machine learning on heterogeneous systems, Software available from tensorflow.org.
[10] Barsoum, E., Zhang, C., Ferrer, C. C., & Zhang, Z. (2016, October). Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction (pp. 279-283).
Comments are closed, but trackbacks and pingbacks are open.